![]()
Frontline Learning Research Vol.13 No. 4 (2025) 1
- 21
ISSN 2295-3159
1Lund University Humanities Lab,
Lund University, Lund, Sweden
2Department of Psychology, Lund University, Lund,
Sweden3Research and Innovation Centre for Open Distance
Education (ECO-lab), Open Universiteit, Heerlen, The Netherlands
4Department of Education, Utrecht University, the
Netherlands
Article received 6 May 2024 / revised 28 July 2025 / accepted 2 October 2025 / available online 31 May 2026
Classrooms, and education in general, are becoming increasingly digital. One novel digital technology that might enter educational settings soon is eye tracking. This is a method to estimate a person’s gaze direction and infer the point of visual attention. This technology has already provided insights into how students process computer-based instructional material. Moreover, it has been used to enhance pre-recorded video instruction, by showing learners where the teacher is looking, which made it easier for learners to follow and learn from the teacher (i.e., eye movement modeling examples; EMME). Thus far, EMME has been implemented only in pre-recorded videos. In the current paper, we present a proof-of-concept, with a focus on the technical set-up, used in synchronous instruction. We recorded the eye movements of a teacher giving a PowerPoint presentation and displayed his eye-movements in real-time to students who were present in the same classroom. Students saw one of three different versions of the presentation: The PowerPoint only (1), the PowerPoint with an overlay of the teacher’s eye movements as a circle (2) or as an inversed blurring of the material (3). Both types of EMME significantly affected how closely students followed the teacher’s gaze, but had no impact on learning. We discuss results in comparison to previous findings on pre-recorded EMME and possible future applications in educational practice.
Keywords:eye tracking; digital classroom; eye movement modeling examples; cueing
Since the early 20th century, when the first eye tracker was introduced, eye tracking technology has been instrumental in studying cognitive processes and their relation to attention allocation and eye movements. One general conclusion is that cognitive processes drive eye movements (Rayner, 1992, 2009). Indeed, eye tracking has proven very useful to better understand learning and instruction and is increasingly being used in educational research according to recent reviews (Alemdag & Cagiltay, 2018; Coskun & Cagiltay, 2022; Jarodzka et al., 2017; Lai et al., 2013; Strohmaier et al., 2020). These reviews show that eye tracking has revealed new insights on the design of instructional material (Coskun & Cagiltay, 2022; Jarodzka et al., 2017; Lai et al., 2013), professional expertise development (Gegenfurtner et al., 2011; Jarodzka et al., 2017; Sheridan & Reingold, 2017), individual differences in learning (Alemdag & Cagiltay, 2018; Lai et al., 2013), learning strategies (Lai et al., 2013; Strohmaier et al., 2020) and many more.
In recent years, however, researchers have begun asking whether the reverse is also true: can eye movements not only reflect but also drive cognitive processes (Grant & Spivey, 2003; Van Gog & Scheiter, 2010)? From decades of eye tracking research, we know that novices in a domain are often distracted by information that is visually salient, thereby overlooking thematically relevant content (Gegenfurtner et al., 2011; Jarodzka et al., 2017; Sheridan & Reingold, 2017; Van der Gijp et al., 2017). While adding visual cues to highlight relevant areas may help to guide novices’ attention to the relevant information at the right time (de Koning et al., 2009; Mautone & Mayer, 2001; van Gog, 2021), eye tracking may offer a more direct solution to do so. Research has shown that students’ attention can be guided by the eye movements of experts (Grant & Spivey, 2003; Velichkovsky, 1995). This insight, combined with the well-established notion that humans learn efficiently by observing others (Bandura, 1977; Meltzoff & Moore, 1977), has given rise to the concept of Eye Movement Modelling Examples (EMME). EMME are instructional videos in which an individual, typically an expert model or a teacher, demonstrates how to perform a task to the learner, with the model’s eye movements overlaid as visual cues over the task material (Van Gog et al., 2009; Jarodzka et al., 2013). EMME serve two main functions that are both aimed at improving the learner’s skills and learning experience; seeing where the model is looking when performing the task can help to 1) synchronize the students’ with the model’s gaze, thereby fostering comprehension of the model’s demonstration and explanation, and 2) give students insight into the perceptual/cognitive strategies the model is using during task performance, which would otherwise not be observable for students (Van Gog et al., 2024).
Since then, numerous studies have demonstrated how EMME can help guide learners’ attention during tasks and enhance their learning outcomes (some examples: Jarodzka et al., 2012, 2013; Krebs et al., 2019; Litchfield et al., 2010; Van Marlen et al., 2016). However, there are some inconsistencies regarding the results of EMME, especially regarding their effects on learning outcomes. Three recent literature reviews discussing EMME research and similar eye movement modeling applications (Emhardt et al., 2023; Tunga & Cagiltay, 2023; Xie et al., 2021) all highlight that the effectiveness of EMME depends on various factors, such as prior knowledge, participant sample, and instructor behavior. In addition, these reviews reveal one significant gap that remains within the body of literature on EMME, namely that, so far, research has been restricted to pre-recorded EMME. These require that a model (e.g., a teacher, an expert, or a peer) comes into an eye tracking lab to record their eye movements while completing a task. These recordings are then produced into a video and later shown to learners, which is a time- and labor-intensive process (although with the potential to reach numerous students once recorded). With the rapid development of eye trackers, which are becoming smaller, more lightweight, and sometimes even already built into everyday devices, such as smartphones (Apple, Huawei, Samsung), cars (Volvo), or laptops (Alienware), new opportunities for eye-movement applications in learning and instruction arise. Specifically, these developments enable using EMME in real-time, synchronously with the teaching activity. In this paper, we will refer to real-time EMME applications as synchronous EMME. Example settings where synchronous EMME could be used as an add-on are computer-based classroom instruction and online education. In such settings, EMME could be used adaptively based on the current interaction with the learners (i.e., adaptive instruction). However, similar to pre-recorded EMME, moderating factors need to be considered to maximize the benefits of EMME. Specifically for synchronous EMME, in this discussion we focus on two key moderating factors: the task type and the design of the EMME.
EMME have been tested across a wide range of learning scenarios and tasks. Xie et al. (2021) adopt the common distinction between procedural and non-procedural tasks (originally by Van Marlen et al., 2016). In non-procedural tasks, the modelled task is generally non-interactive. It involves the model showing, for example, a decision-making process, a problem-solving strategy or a classification approach (e.g., in Jarodzka et al., 2010; Litchfield et al., 2010; Wang et al., 2020). Procedural tasks, by contrast, require the model to interact with the task interface. It involves explaining and showing active procedures and applied skills to complete tasks, e.g., writing code or solving mathematical problems (Emhardt et al., 2022; Van Marlen et al., 2016). The meta-analysis of Xie et al. (2021) showed that EMME generally only have a positive effect on learning outcomes in non-procedural tasks. However, Emhardt et al. (2023) highlight that it may be beneficial to identify tasks on a more detailed level. Tasks vary widely in their requirements and goals. They conclude that it is the visual component in the task that plays a significant role. Tasks with more important visual components, such as classification tasks, visuo-motor tasks or text processing/comprehension tasks, likely benefit more from EMME compared to (procedural) problem-solving tasks. Based on this assumption, synchronous EMME may be more beneficial in image-based instruction (e.g., teaching how to read x-rays or explaining the anatomy of the eye), rather than practical instruction (e.g., showing how to solve mathematical equations).
Design choices also influence EMME’s effectiveness. Two key aspects are whether the EMME include audio and how the eye movements are displayed. Regarding the first aspect, i.e., verbalization, Van Gog et al. (2009) found the combination of EMME and verbalization to have detrimental effects on performance compared to having either the EMME or the verbalization alone. However, in the review of Tunga and Cagiltay (2023), they conclude that in most studies the inclusion of a verbal explanation has no detrimental effects on the effectiveness of EMME (cf., Tunga & Cagiltay, 2023). The meta-analysis of Xie et al. (2021) aligns with this finding, but does report a slightly smaller effect size for EMME including verbal explanations. One reason may be that the gaze and verbal commentary may be redundant, in which case learning is hampered. When the gaze disambiguates the verbal explanations, EMME do seem effective for learning (e.g., Van Marlen et al., 2018). Synchronous instruction will, in most cases, include a verbal component as well. Both the verbal instructions and the eye movements may be less coherent or contain more ‘noise’ than in pre-recorded EMME, which can be re-recorded or edited if necessary. An important consideration for synchronous EMME therefore is that synchronized verbalization may reduce the EMME’s effectiveness, depending on whether the verbal explanations and gaze are redundant or whether gaze disambiguates the verbal explanation.
The second aspect, i.e., the design of the visual cue presenting the model’s eye movements, has received significantly less attention. There are various ways to present the model’s eye movements, such as by showing a colorful dot or circle where the momentary visual focus of the model is, or by reducing the visual input by blurring out the not-attended-to areas instead (Jarodzka et al., 2012; Krebs et al., 2021; Nyström & Holmqvist, 2008; Vig et al., 2012). The latter is an example of inverse cueing or anti-cueing (Lowe & Boucheix, 2011). There is not much empirical research that compared these two forms of cueing, but the few available studies suggest that blurring out not-attended-to information guides students’ visual attention best, while adding a dot to indicate the model’s visual focus leads to best learning outcomes (Jarodzka et al., 2012, 2013; Zhang et al., 2017).
Taking it all together, the three recent reviews on EMME research (Xie et al., 2021; Emhardt et al., 2022; Tunga & Cagiltay, 2022) agree that EMME are generally effective instructional tools as long as the instructed (preferably non-procedural) task has a significant visual component and there are minimal distractions. Distractions are, for instance, visible cues for approaching the task other than the teacher’s gaze, such as a cursor, but also verbal information. According to the aforementioned reviews, verbal information does not negate the effect of EMME but does reduce its effect size. To ensure the observer’s focus aligns more closely to the modelled eye movements, visualization techniques that minimize distractions can be used. An example of this is using an inverse cue blurring out the areas not attended by the model, although this may come at the cost of reduced learning outcomes. In sum, as underlined in the aforementioned reviews, more research into EMMEs is required to maximize their benefits. Furthermore, with the rapid development of technology in mind, both the implementation of synchronous EMME as well as its optimization need to be explored.
The present study serves as a proof-of-concept, demonstrating the use of real-time EMME in synchronous instruction, exploring its potential to enhance student learning outcomes through improved visual focus alignment and visual support. We compared two designs of EMME, using a circle to show the center of visual attention, vs. blurring out all areas except the center of attention, to a control condition without any cueing based on the teacher’s eye movements. We conducted the study in a digital classroom (a computer room). This setting is similar to an online setting, which will likely be the easier setting to apply synchronous EMME in the future. This digital classroom was uniquely outfitted to allow for high-fidelity eye tracking, and designed to allow the teacher’s eye movements to be shown in real time to students whose visual focus was also recorded through eye tracking.
To stimulate both realism and EMME effectiveness, the instruction included a verbal component, was non-procedural, and had a strong visual component. Specifically, the learning goal of the lecture was to provide learners with a conceptual understanding of the eye and eye-tracking, which entailed supporting students in building comprehensive mental models of complex visual information (e.g., the anatomy of the human eye; the processing of visual information). Their understanding would then be tested after the instruction using a questionnaire consisting of open-ended questions that tested more than mere memorization (e.g., “How are images formed and transmitted to the brain?”). Given that the study was explorative, we did not formulate a priori hypotheses. However, based on the setting of our study and our expectation that results would be consistent with prior pre-recorded EMME research, we have formulated the following expectations:
E1: Visual Focus Alignment
- E1a: displaying the teacher’s eye movements via EMME will enhance students’ ability to align their visual attention with the visual focus of the teacher during synchronous classroom instruction.
- E1b: an inversed blurring cue will lead to closer student-teacher visual alignment compared to a circle cue.
E2: Learning Outcomes
- E2a: integrating EMME into synchronous classroom instruction will improve students’ learning outcomes compared to students who do not receive EMME.
- E2b: a circle cue will lead to higher learning outcomes compared to an inversed blurring cue.
In addition to investigating the effect of synchronous EMME on visual focus alignment and learning outcomes, we were interested in the students’ experience of the synchronous EMME setting, particularly the impact of synchronous EMME on their engagement and perceived learning support. While synchronous EMME could lower the threshold to implementing EMME in instruction as it does not require time-consuming post-production, EMME is likely to have adverse effects when it is not appreciated by the students.
R1: Student Experience Evaluation
- How do students perceive and evaluate their learning experience when EMME is incorporated into the teaching process?
Forty-four adult students in a Biomedical Engineering lab course about eye tracking participated in this study (age mean: 20.4 yrs; SD = 1.4 yrs; 16 males and 26 females; 2 did not disclose age and gender). The data were collected in three sessions with 14, 16, and 15 students, respectively (one student declined to participate in the study and was thus not included in the sample). All provided informed consent.
The experiment had a between-subject design, wherein students within each classroom session were randomly assigned to one of three EMME conditions: (1) No Cue (control): students viewed the learning material as the teacher saw it without any additional cues; (2) Circle Cue: a red circle, with an 80-pixel outer diameter and 72-pixel inner diameter (corresponding to 1.9° and 1.7° of visual angle at a 65 cm viewing distance, respectively), was superimposed on the learning material to indicate the teacher’s visual focus (see Figure 1, left panel); (3) Blur Cue: the entirety of the learning material was blurred, except for the area of the teacher’s visual focus. This area remained sharp, creating a focal point of clarity within a blurred field. The sharp area was defined by a window with a 100-pixel radius (2.4° of visual angle), beyond which the image transitioned from sharp to blurred over an additional 50 pixels (1.2°) using a raised cosine function to ensure a smooth gradient between the focused and unfocused areas (see Figure 1, right panel).
Figure 1
The circle (left) and blur (right) cues.

In the EMME conditions, gaze data from the teacher was transmitted to the student stations at a frequency of 600 Hz. To enhance the visualizations’ clarity by minimizing jitter, a critical step involved filtering the gaze data to reduce noise. For this purpose, the Olsson (2007) filter was employed, selected for its efficacy in balancing noise reduction during fixations without compromising the integrity of saccadic movements, as validated by (Špakov, 2012). Initially, the gaze cue was displayed to students at the refresh rate of their computer screens, which was 60 Hz. However, technical issues arose during the lectures, leading to a decrease in the display rate to between 3 and 5 Hz by the end of the sessions. Despite this reduction in refresh rate, the overall quality of the gaze cue visualization remained largely unaffected. This resilience can be attributed to the filtering process, which resulted in a display characterized by periods of stability punctuated by quick transitions, mirroring natural eye movement behavior. Furthermore, these technical challenges did not compromise our analysis, which focused on evaluating student gaze patterns in response to the displayed cues rather than the temporal fidelity of cue presentation.
At the beginning of a 2-hour lab session about eye-trackers, students were briefly introduced to the Lund University Humanities Lab Digital Classroom and each took a seat at their own computer-station. The Digital Classroom (Niehorster, Gullberg & Nyström, 2024) consists of 15 eye-tracked student stations along with an eye-tracked teacher station (see Figure 2). Each of these eye-tracking stations were equipped with a Dell laptop (closed lid) and a Tobii Pro Spectrum eye tracker (firmware version 1.7.6-sclera-0), which recorded the participant’s gaze location from both eyes at 600 Hz. The eye tracker recorded horizontal and vertical gaze positions in normalized units on the screen attached to the eye tracker, where (0,0) corresponds to the upper left corner and (1,1) to the lower right corner of the screen. These computer screens were EIZO FlexScan EV2451 52.8 x 29.7 cm monitors that had a 1920x1080 pixel resolution. The eye trackers were set up and controlled using the Titta package (Niehorster et al., 2020). The stations were connected with a Gigabit ethernet switch (Cisco SG500-52), enabling transfer of gaze data from the teacher station to the student stations at latencies of less than 1 ms (Nyström et al., 2017). For streaming of the eye-tracking data as well as other communication between the experiment stations, the UDPMulticast package was used (github.com/dcnieho/UDPMulticast; c.f., Niehorster et al., 2019) . As shown in Figures 2 and 3, the student stations were set up along three legs of a large square layout, with all students facing inwards and able to see each other. To ensure the teacher and the students would focus on their screens, privacy dividers were placed around the desk where the teacher was positioned. In doing so, the teacher was hidden from students’ view, which is also more akin to an online teaching environment. The room was brightly lit with fluorescent lighting, and no outdoor lighting could penetrate the room.
Figure 2
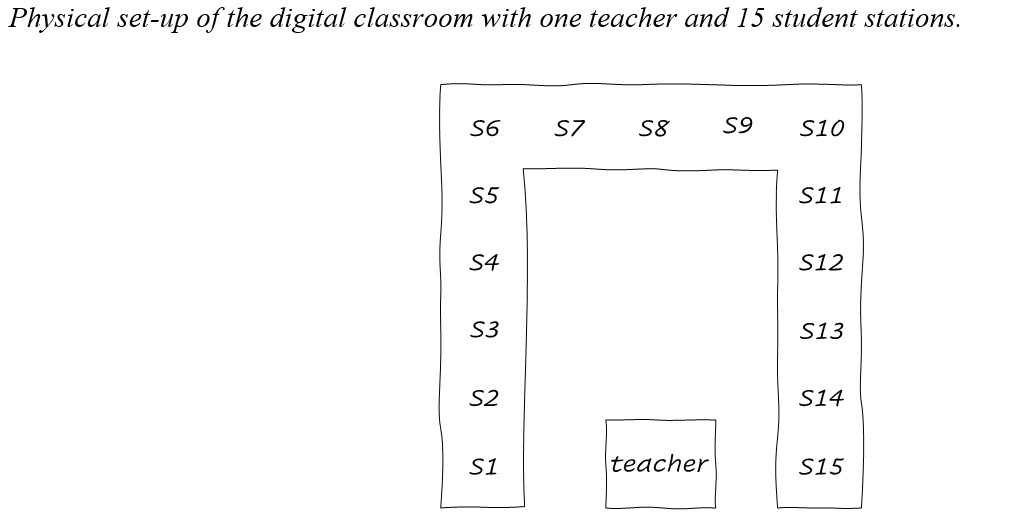
Figure 3
Photo of the recording set-up. Left: from a student’s perspective (‘blurred’ condition). Right: from the teacher’s perspective.

After students were seated, the teacher explained that the session would start with a brief lecture about human vision, eye movements, and eye-trackers, and that they would be able to hear him but not see him, while their eye movements on the lecture materials would be recorded. This course is regularly given to students of Biomedical Engineering. The lecture materials (detailed below) had been used for previous iterations of the course over several years and were not altered for use in the experiment. Participation was voluntary and all students agreed ahead of time. One student asked to remove their data after the session, which was done immediately. After this, the eye trackers at all stations were calibrated using a 5-point default calibration procedure of the Titta package followed by a 4-point validation of the calibration (median accuracy 0.63˚, mean accuracy 1.02˚ (STD 0.99˚) for students, and mean 0.34˚ (STD 0.09˚) for the teacher) and participants received written on-screen instructions depending on the condition to which they were assigned. If they were assigned to one of the EMME cue conditions, they read that they would see what the teacher was currently focusing on by means of either a red ring, or by blurring the screen everywhere that the teacher was not looking.
The teacher then gave a lecture based on a PowerPoint presentation consisting of 18 slides on the topic of eye tracking (see Supplementary Material 1 for the slides). The slides varied in visual content, ranging from slides with only text elements to slides containing complex diagrams, as well as combinations of text and picture elements. Text elements consisted of only a few words, and as such would not elicit extensive reading by the teacher. On each station, the PowerPoint slides of the lecture were presented using a custom program written in MATLAB (Natick, MA) that used the PsychToolbox package (Brainard, 1997; Kleiner et al., 2007; Pelli, 1997) for presentation. Communication between the stations over the network included informing the software running on the student stations which EMME cue condition it should display during a recording and signals indicating that the teacher navigated to another slide, prompting the new slide to be displayed on the student stations as well.
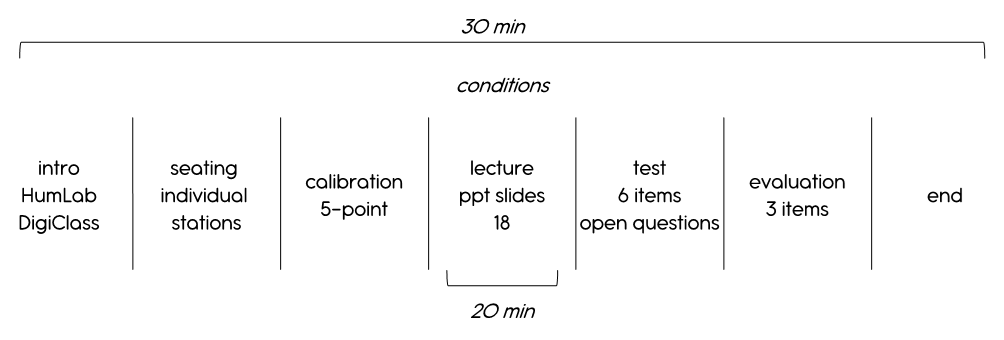
After this lecture that lasted about 20 minutes, the students were presented with an unexpected knowledge test in the form of a 6-item questionnaire with open questions about the lecture content. These were simple knowledge questions about content covered in class for which no elaborative processing was required. Finally, all students were asked to answer an evaluation question about the teaching situation: “What are your thoughts of this form of lecturing compared to standard face-to-face lecturing?” (open answer format). Additionally, students in the EMME condition were asked two further evaluation questions about the EMME cue: “Did you find the cue helpful?” and “Did you find the cue disturbing?”. They answered by providing a numerical rating on a ten-point scale of how helpful or disturbing the EMME cue was and could elaborate on their answer. For an overview of the entire experimental procedure, see Figure 4.
Figure 4
Overview of the experimental procedure.
To analyze gaze behavior, we first classified the gaze data streams of each student into fixations using the I2MC algorithm (Hessels et al., 2017) v.2.0.3 with default settings, except that classified fixations shorter than 60 ms were removed, and that fixations closer together than 15 pixels (0.36° at a 65cm viewing distance) were merged into a single fixation. Saccades were defined as the transition between different classified fixations. Only intervals between fixations shorter than 80 ms containing less than 5% missing data were included as saccades in the analyses.
Alignment of visual attention (E1) was operationalized in two different ways: (1) the spatial alignment and (2) the temporal entrainment of student eye movements with that of the teacher.
First, spatial alignment unravels whether students who received an EMME cue looked closer in space to the teacher’s fixation position than those who did not view a cue. For this analysis, the time series of cue positions displayed on each student’s screen was upsampled (sample and hold) to the frequency of the eye tracker signal (600 Hz). In the no-cue condition, teacher fixation positions were stored for each student station in the same way as for the cue conditions even though it was not shown and could thus be analyzed in the same way. Stable periods in the teacher’s eye movement signal were then classified using the Hooge and Camps (2013) algorithm using default parameters. Stable periods closer together in space than 10 pixels were merged, and stable periods shorter than 100 ms were removed from analysis. Finally, for each student fixation, the stable period in the cue display that temporally overlapped most was selected, and the distance between the student fixation and the cue position was calculated in degrees.
Second, temporal entrainment refers to whether students who received the cue synchronized the timing of their saccades with position changes of the teacher’s cue indicating to which extent their visual behavior was influenced by the cue. For this analysis, we used the same segmentation of the cue into stable and moving periods as created for the spatial alignment analysis. For each teacher saccade (each movement of the cue), the student saccade closest in time was selected and the time interval between their onsets was calculated. A histogram was created of the resulting set of student-teacher saccade intervals for each student, using 10 ms bins.
Learning outcomes were defined as the score on the knowledge test questions. These questions (see Supplementary Material 2) tested students’ understanding of the lecture, inquiring how presented concepts worked (i.e., conceptual understanding) rather than merely testing their memory of the lecture. The answers to the six open questions were scored by assigning a maximum of between 1 and 6 points per question depending on the number of elements that a fully correct answer should contain and then summed, resulting in a knowledge score ranging from 0–18. Two coders (MN & DN) independently coded 20% of the learning outcome data. As a high degree of inter-rater reliability was found between both raters (Cohen's α = .954), only one rater coded the remainder of the data.
We first checked whether the basic oculomotor parameters (fixation duration and saccade amplitude) of the students in the two EMME conditions would (unexpectedly) differ from that of students who did not receive an EMME cue. Mean fixation durations and mean saccade amplitudes are plotted in Figure 5. An ANOVA revealed that there were no significant differences between the cue conditions in either mean fixation duration F(2, 41) = 1.002, p = 0.376, 2 = 0.047 or mean saccade amplitude F(2, 41) = 0.167, p = 0.847, 2 = 0.008, suggesting that overall gaze behavior was comparable across conditions.
Figure 5
Basic oculomotor parameters (fixation duration and saccade amplitude) for the different conditions. For each condition, the mean values for individual participants are indicated by means of gray dots, besides which the mean per condition is denoted by the black dot. Error bars denote 95% CIs.
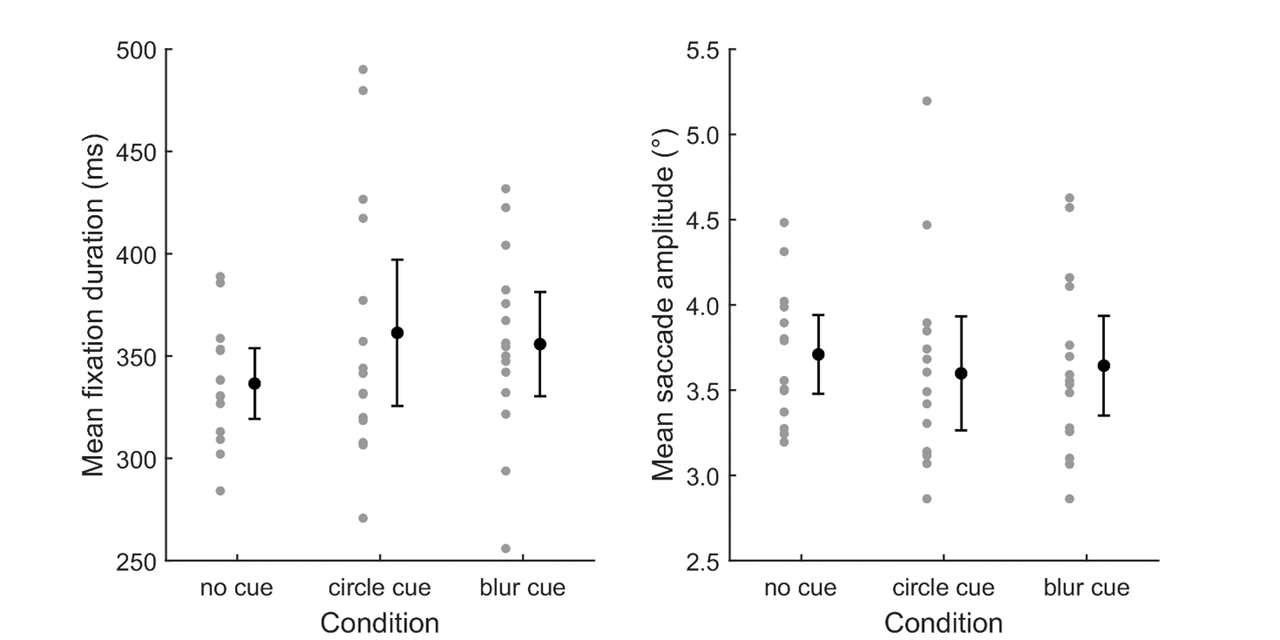
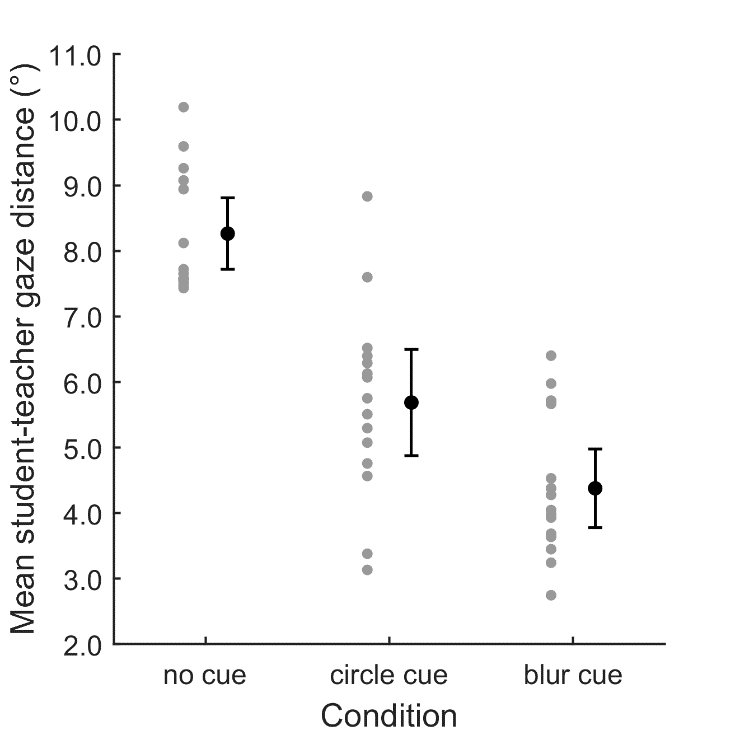
Figure 6 plots the spatial alignment between the students’ gaze position and the teacher’s gaze position, in terms of the mean distance over time. An ANOVA revealed that there were significant differences in spatial alignment of student fixations with teacher fixations between the conditions, F(2, 41) = 39.776, p < 0.001, 2 = 0.660. Planned contrasts revealed that in the EMME conditions, students’ fixations were significantly closer to the teacher’s fixation position than in the no cue condition (E1a; t(41) = -8.379, p < 0.001, d = -5.424), and that student gaze was closer to the teacher’s in the blurred EMME condition than in the circle EMME condition (E1b; t(41) = 3.057, p = 0.004, d = 1.116).
Figure 6
Mean distance between student and teacher fixation positions for the different EMME conditions. For each condition, the mean values for individual participants are indicated by means of gray dots, besides which the mean per condition is denoted by the black dot. Error bars denote 95% CIs.
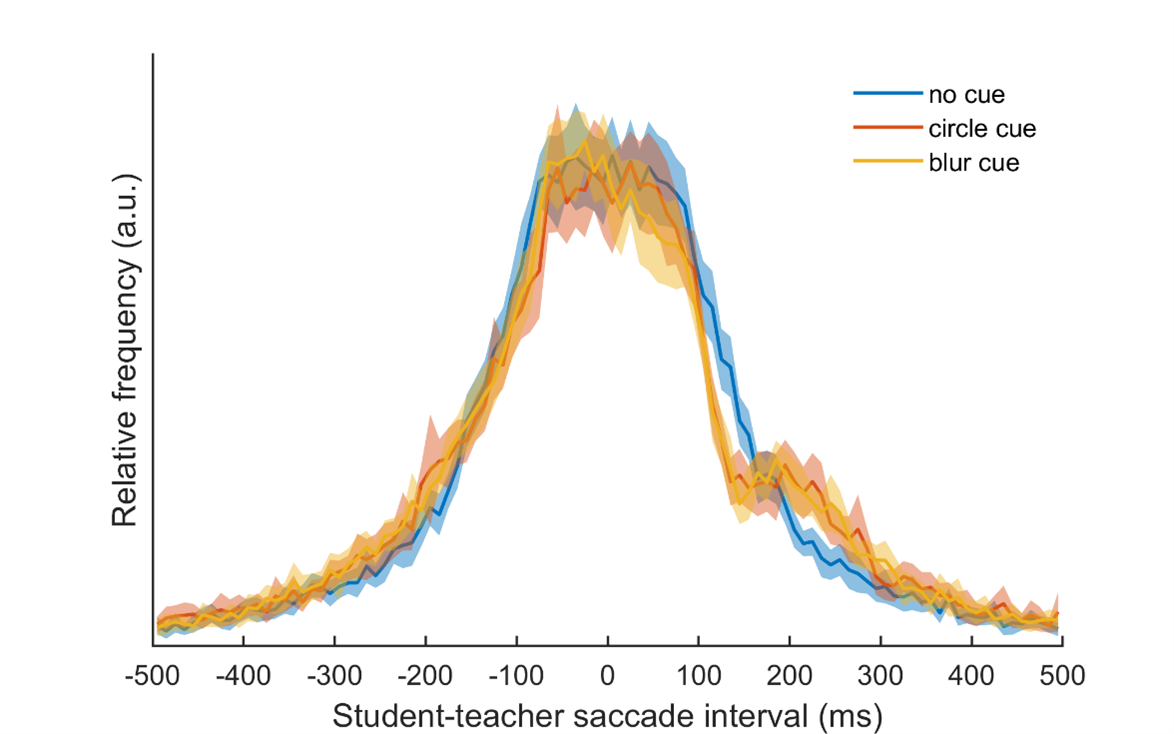
As an indication of the temporal alignment between the students’ and the teacher’s eye movements, Figure 7 shows the histogram of student-teacher saccade intervals for each condition along with the 95% CI. As can be seen because the 95% CIs do not overlap, in the EMME conditions, student saccades are significantly less likely to occur between approximately 100‒150 ms after a teacher saccade than in the no EMME condition, and significantly more likely to occur in the 200‒250 ms interval, consistent with our expectation (E1a). This indicates that students who received EMME first inhibited their own saccades upon receiving the cue (100-150 ms) and only initiated corrective saccades later (200-250 ms). Students who saw no EMME (i.e., no visual cue), showed no such inhibition and correction pattern. As opposed to our expectations, there was no significant difference between the two EMME conditions (E1b).
Figure 7
Histograms showing relative frequency of student saccades as a function of the interval between student and teacher saccades. Shaded areas denote 95% CI. Zero (0) ms on the x-axis refers to the onset of the teacher saccade, and positive values indicate that students initiated a saccade after the teacher.
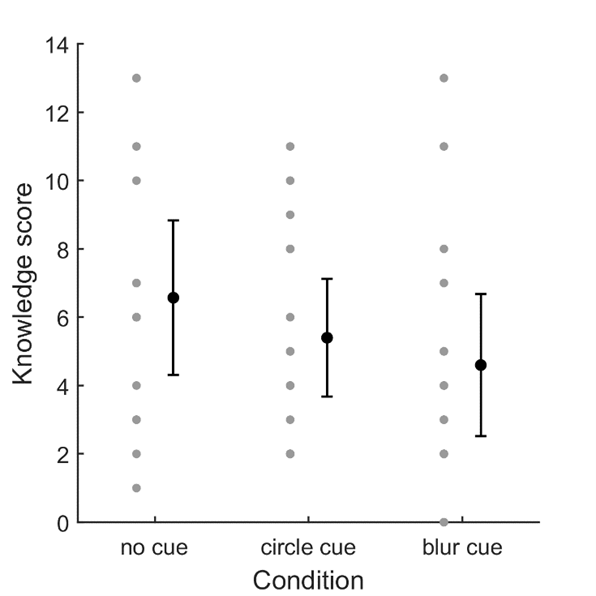
We expected (E2a) that synchronous EMME would lead to higher learning outcomes (displayed in Figure 8), similar to pre-recorded EMME. However, there was no significant effect of EMME on learning outcomes, F(2, 41) = 1.092, p = 0.345, 2 = 0.008. The type of cue did not play a role in this (E2b).
Figure 8
Participant knowledge question scores for the different gaze cue conditions. For each condition, the mean values for individual participants are indicated by means of gray dots, besides which the mean per condition is denoted by the black dot. Error bars denote 95% CIs.
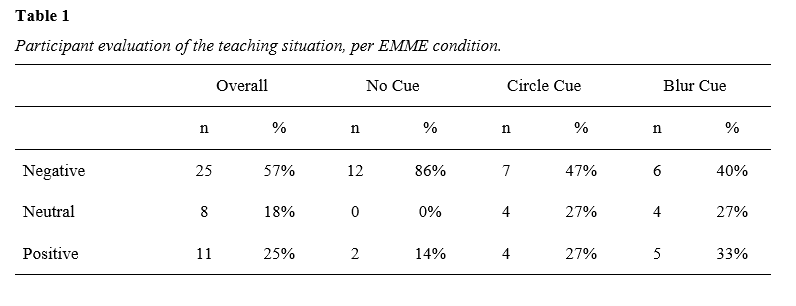
In response to the question “What are your thoughts of this form of lecturing compared to standard face-to-face lecturing?”, which was asked to all participants, the overall data (see Table 1) show that most (57%) expressed negative attitudes such as difficulty to concentrate, and missing the teacher’s body language. Interestingly, however, when breaking it down by condition, it is clear that students who did not receive EMME overwhelmingly (86%) judged the teaching situation negatively, while among students in the EMME conditions, only 43% judged the teaching situation negatively. Examples of negative comments included “prefer standard face-to-face, easier to stay focused” and “the lack of seeing the lecturer means that some information that is expressed through body language is lost”. Negative evaluations of the teaching situation by students who did not view an EMME cue were predominantly due to difficulty concentrating since they could not see the teacher.
Overall, 18% of participants evaluated the setting neutrally, as exemplified by comments such as “feels very intensive, compared to a normal lecture, but it seems like you focus more on what is being said” and “it was interesting but sometimes hard to concentrate”, and 25% evaluated the setting positively, as evidenced by comments such as “it made it easier to follow since you knew where you should look and I listened better” and “I think this was a good form of lecturing. I think that it was easier to keep focus on the right thing”. The amount of neutral and positive evaluations seemed higher (judging by the descriptive statistics in Table 1) in the EMME conditions than in the No EMME condition.
Table 1
Participant evaluation of the teaching situation, per EMME condition.
Regarding the evaluation of the EMME cues, Figure 9 presents the ratings of the perceived helpfulness and distraction per EMME condition. While ratings of the helpfulness of the cue were lower for the blur cue than for the circle cue, this difference did not reach statistical significance (t(26) = ‒1.94, p = 0.063). However, ratings for perceived distraction were significantly higher for the blur cue than for the circle cue (t(24) = 2.70, p = 0.012). Additional textual explanations suggested that whether either of the cues was perceived as helpful or distracting depended on the specific learning material. For both cues, participants mostly seemed to find them useful when visually complex material was being presented, as exemplified by the comment “especially helpful when looking at the anatomy of the eye” of a participant who received the blur cue, and “when looking at pictures with a lot of information it was incredibly useful as a tool to know what the lecturer was talking about” of a participant who saw the circle cue. Participants in the blur EMME condition commented that the blur cue interfered with visual exploration at times, e.g., “frustrating to not be able to see everything you wanted” and “felt like I had blind spots”. Participants in the circle EMME condition explained they found the cue distracting because “it was distracting when the gaze tracer looked at something other than what you were talking about” and “just generally hard to focus on what he was talking about when the circle was moving a lot”.
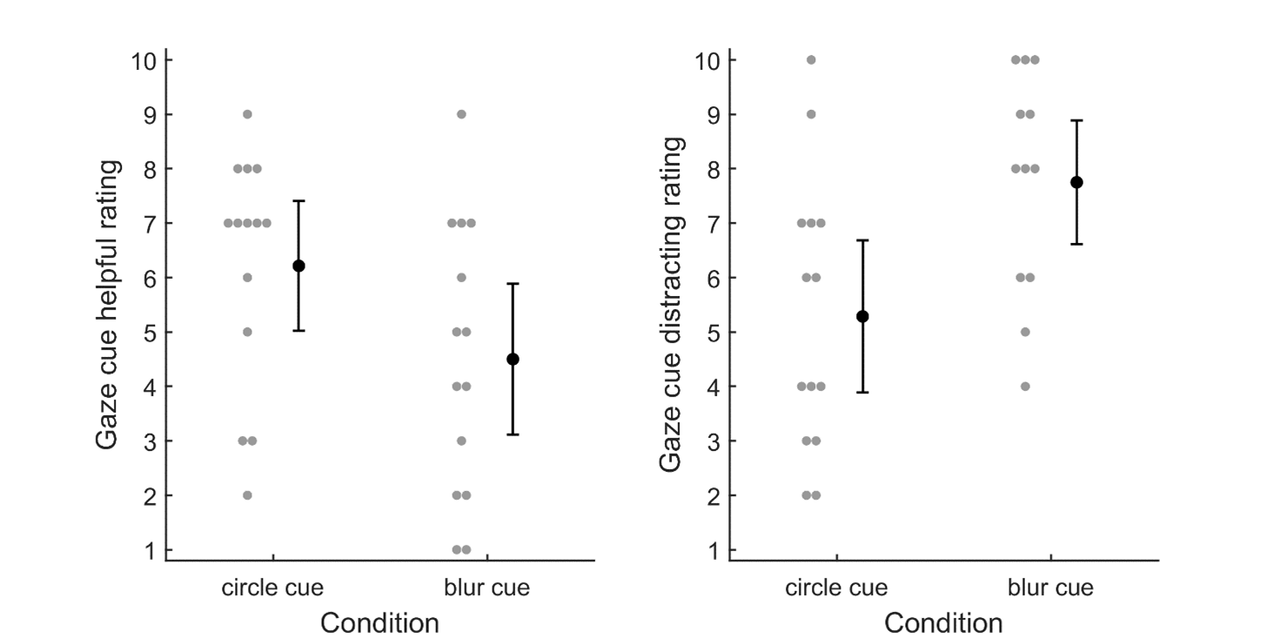
Figure 9
Participant ratings indicating how helpful and how distracting the different EMME conditions were. For each condition, the mean values for individual participants are indicated by means of gray dots, besides which the mean per condition is denoted by the black dot. Error bars denote 95% CIs.
The first objective of this study was to provide a proof-of-concept of synchronous EMME in a digital classroom (similar to an online classroom setting) using real-time eye tracking technology and investigate whether they yield similar effects to pre-recorded EMME. The effectiveness of EMME for aligning students’ attention with that of the teacher, and thereby improving learning outcomes, has been demonstrated for a variety of tasks and learners with pre-recorded videos (Emhardt et al., 2023; Tunga & Cagiltay, 2023; Xie et al., 2021). Synchronous EMME can hold significant benefits over pre-recorded EMME. Recording EMME requires a model to come into the lab, which is labor- and time-intensive, and does not allow the cueing to be adapted to the current interaction with the learners. As such, synchronous EMME may allow broadening the scope in which EMME can be implemented.
The second objective was to explore potential effects of the cue design in EMME. In doing so, we take a first step into exploring synchronous EMME design, as well as add to the existing body of research on EMME.
Pre-recorded EMME were found to enhance the alignment of students’ visual attention with the visual focus of the teacher (cf. Emhardt et al., 2023; Tunga & Cagiltay, 2023; Xie et al., 2021). Our findings show that the same effect occurs when synchronous EMME is used, in line with our expectation (E1a). This was evidenced by significantly higher spatial alignment between student fixations and teacher fixations in the EMME conditions than in the no EMME condition, and the findings regarding temporal entrainment (Figure 7) support this conclusion.
The alignment of visual attention is considered important for following the teacher’s verbal explanation, and thereby, enhance learning outcomes. Research on pre-recorded EMME showed the effect of EMME on learning outcomes to be dependent on a large number of factors. Despite our efforts to create an environment where a positive effect of EMME on learning outcomes could be expected, no significant improvement of students' learning outcomes was found when comparing students who received the lecture with synchronous EMME to students without cues (E2a). One explanation would be that in synchronous EMME there is more ‘noise’. Pre-recorded EMME can be post-edited or re-recorded if the teacher focuses on non-essential parts during the instruction. This is not possible for synchronous EMME, meaning it may contain gaze behavior that is not related to the instructional task or relevant for learning, but instead reflects moments of the teachers’ cognitive processing, e.g., randomly placed fixations when the teacher thought about verbal phrasing during the instruction. When students’ attention is aligned and they follow those eye movements of the teacher too, this will not foster their learning (and might even be slightly confusing in some cases). Alternatively, EMME may have enhanced visual attention alignment without impacting learning because the guidance was not (always) necessary for students; for instance, when their prior knowledge also allowed students in the no-EMME control condition to look at the right information at the time it was mentioned, or when their available cognitive capacity allowed them to catch on even when they were not aligned for a moment. In those cases, the attention guidance may not have been necessary for them to be able to follow the teacher’s verbal explanation, which, again, mirrors findings of prior research with pre-recorded EMME (e.g., Van Marlen et al., 2018) and other types of visual cues in videos and animations (van Gog, 2021). Still, we have to be cautious in interpreting this finding, because given our relatively small sample size, we may not have sufficient statistical power to detect a significant effect on learning outcomes, especially considering the report by Xie et al. (2021) that verbalized EMME may yield smaller effects.
Lastly, focusing on the usability of synchronous EMME, we inquired about the students’ perceptions of the teaching format and the evaluation of their learning experiences. Results showed they were far less negative about the experience when they received EMME (43%) than when they did not (86%), revealing a positive attitude towards EMME. The results suggest that the presence of visual cues can mitigate some of the challenges associated with following the lecture in a digital/computer-oriented teaching session where students cannot see the teacher (similar to online lectures), although some students (Figure 9) commented that the visual cue was distracting or frustrating. Again, the synchronous instruction, which will likely always include verbalization, may have had an impact on their experiences with EMME. Still, several students specifically remarked that EMME were most useful when the materials were more (visually) complex, confirming earlier findings on pre-recorded EMME where it was found to be most beneficial for visually complex tasks (cf. Emhardt et al., 2023; Tunga & Cagiltay, 2023; Xie et al., 2021). In view of this, it would be interesting for future research to investigate the option of the teacher turning the gaze cues on and off depending on the complexity of the materials, or to have students themselves decide when to turn it on and off (cf., Špakov et al., 2019).
Very few studies so far have investigated the effects of different ways of displaying eye movements in EMME (see Emhardt et al., 2023). Regarding differences between the two types of EMME, we found a significant difference in terms of alignment of visual attention, with the blur cue being more effective for aligning students' visual focus with the teacher's than the circle cue, but not in learning outcomes, in line with our first expectation (E1b) but not our second (E2b). The finding that blurring out the information not currently fixated by the teacher is more effective for aligning visual attention than a circle cue, is in line with findings by Jarodzka et al. (2012, 2013). However, we should note that this may in part be because this cue is also more enforcing (i.e., the learner can opt to look elsewhere but will not be able to see any details there), which some students indicated in the evaluation questions to find quite frustrating.
This may also explain why the blurring cue is not necessarily better for learning even if it aligns attention more effectively. Not only did our study show no differences in learning outcomes between the cue types (which again, could have been due to the relatively small sample size), but findings from prior research are also inconclusive. One study by Jarodzka et al. (2012) on diagnosing motor movements in small infants found beneficial effects of blurring compared to a circle. Another study by Jarodzka et al. (2013) on classifying fish locomotion patterns and a study by Brams et al. (2021) on diagnosing lung X-rays, found beneficial effects of a circle cue. These different findings are likely due to the characteristics of the learning material used in the studies. For instance, when a quick and subtle motor movement in a part of a small infant’s body is missed, it will be very hard to learn to diagnose this, so the enforcing nature of the blurring cue might be really functional here. Also, it is possible that the bright circle cue made it harder to observe the motor movement in these materials, which would be less of a problem in the other types of materials. So, while our findings suggest that the blur cue may be more effective for directing attention, its coercive nature might undermine learning in specific tasks, which highlight the need to consider the type of material before deciding on which cue to use. Further exploration is warranted in more systematic future research.
Our study makes an important novel contribution to the literature, by showing that synchronous EMME can be employed successfully and yield similar benefits to pre-recorded EMME, which underlines the potential of EMME in various synchronous education settings. However, contrary to our expectations, we did not find an effect of synchronous EMME on learning outcomes, which warrants further investigation before it can be successfully implemented in classrooms. Additionally, there are several limitations that should be acknowledged, which also open avenues for future research.
First, the present study used a digital classroom setting which was highly controlled and in which the teacher was hidden from students’ view to ensure visual attention was on the screen. While this is comparable to an online teaching setting, we acknowledge that this setting in a small classroom is rather artificial. A digital classroom without privacy dividers might add other distractions, impacting effects of synchronous EMME, and an authentic online teaching session is subject to many more external influences (e.g., students being on their phone and not looking at the screen). It would be interesting to explore these more flexible scenarios and contexts. Future research should also investigate to what extent our findings can be replicated and expanded to other real-time, synchronous teaching scenarios, such as large lecture halls or during synchronous lecturing in online learning environments using webcam-based eye trackers.
Second, as discussed, EMME have two main functions (Van Gog et al., 2024): 1) synchronizing the students’ gaze with the model’s gaze, which can aid the comprehension of the model’s demonstration and explanation, and 2) giving students insight into the perceptual or cognitive strategies the model uses to perform the task, which would otherwise not be observable for them. The focus in the current study was on the first function of EMME. It would however be interesting to explore in future research whether synchronous EMME can be used to visualize and teach viewing strategies (i.e., EMME’s second function) in large-scale classroom education on topics such as medical education.
Third, due to the exploratory nature of our study, our sample size was relatively small. While this was probably not a problem for the analyses of the eye movement data, we may not have had sufficient power for detecting effects on learning outcomes. Given that we have demonstrated the technical possibility of conducting synchronous EMME research in the present study, future research can apply this to larger and more diverse samples.
Finally, when EMME are taken into actual classrooms and one would also want to monitor students’ alignment with the teacher in such contexts (e.g., to give personalized feedback to the students, or to give feedback to the teacher, using learning analytics dashboards), ethical and privacy concerns come into play. Eye tracking involves processing of personal data, so this would require the development of robust data protection measures and transparent communication with students and teachers about how the use, storage, and disposal of their data can be ensured.
To conclude, the present study took a significant step towards increasing our understanding of the potential uses of eye tracking technology in the classroom. We showed how eye tracking can be employed to bring a specific instructional method (EMME) directly into the classroom in a time-efficient manner. This novel, synchronous application of EMME helped align students’ visual attention to that of the teacher, by displaying the teacher’s gaze to students. We found no effects of EMME on learning outcomes in the present study, which warrants further investigation of the impact of synchronicity, in EMME. Larger sample sizes may also shed further light on the matter. Students who saw the teacher’s gaze reported that they found this especially helpful when the lecture material was more (visually) complex, but they also sometimes found the cues to be frustrating or distracting. Considering these findings largely match earlier studies on pre-recorded EMME, we are convinced synchronous EMME can be applied to improve learning experiences in the future. However, before this can happen, our findings highlight the need for more systematic research on effects of gaze cue design and learning content, which we (and others) can start to conduct, now that we have shown the technological feasibility of using EMME in synchronous instruction in this study.
Supplementary material 1: All lecture slides used as material in this study.
Supplementary material 2: Questionnaire presented after the recording session.
We would like to thank William Rosengren for his support in this study during the data collection.
Authors Diederick Niehorster and Marcus Nyström are owners of eye tracking consulting companies (DC Target AB and Emnys Consulting AB, respectively).
Alemdag, E., & Cagiltay, K. (2018). A systematic review of eye
tracking research on multimedia learning. Computers &
Education, 125 , 413–428.
https://doi.org/10.1016/j.compedu.2018.06.023
Bandura, A. (1977). Social learning theory.
Prentice-Hall.
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial
Vision, 10(4), 433–436.
https://doi.org/10.1163/156856897X00357
Brams, S., Ziv, G., Hooge, I. T., Levin, O., Verschakelen, J.,
Mark Williams, A., Wagemans, J., & Helsen, W. F. (2021).
Training focal lung pathology detection using an eye movement
modeling example. Journal of Medical Imaging , 8(02).
https://doi.org/10.1117/1.JMI.8.2.025501
Coskun, A., & Cagiltay, K. (2022). A systematic review of
eye‐tracking‐based research on animated multimedia learning.
Journal of Computer Assisted Learning , 38(2),
581–598.
https://doi.org/10.1111/jcal.12629
de Koning, B. B., Tabbers, H. K., Rikers, R. M. J. P., & Paas,
F. (2009). Attention guidance in learning from a complex
animation: Seeing is understanding? Learning and Instruction,
in press.
Emhardt, S. N., Jarodzka, H., Brand-Gruwel, S., Drumm, C.,
Niehorster, D. C., & van Gog, T. (2022). What is my teacher
talking about? Effects of displaying the teacher’s gaze and mouse
cursor cues in video lectures on students’ learning. Journal
of Cognitive Psychology, 1–19.
https://doi.org/10.1080/20445911.2022.2080831
Emhardt, S. N., Kok, E., van Gog, T., Brandt-Gruwel, S., van
Marlen, T., & Jarodzka, H. (2023). Visualizing a Task
Performer’s Gaze to Foster Observers’ Performance and Learning—A
Systematic Literature Review on Eye Movement Modeling Examples. Educational
Psychology Review, 35 (1), 23.
https://doi.org/10.1007/s10648-023-09731-7
Gegenfurtner, A., Lehtinen, E., & Säljö, R. (2011). Expertise
differences in the comprehension of visualizations: A
meta-analysis of eye-tracking research in professional domains.
Educational Psychology Review , 23(4), 523–552.
https://doi.org/10.1007/s10648-011-9174-7
Grant, E. R., & Spivey, M. J. (2003). Eye Movements and
Problem Solving: Guiding Attention Guides Thought. Psychological
Science, 14 (5), 462–466.
https://doi.org/10.1111/1467-9280.02454
Hessels, R. S., Niehorster, D. C., Kemner, C., & Hooge, I. T.
C. (2017). Noise-robust fixation detection in eye movement data:
Identification by two-means clustering (I2MC). Behavior
Research Methods, 49 (5), 1802–1823.
https://doi.org/10.3758/s13428-016-0822-1
Hooge, I., & Camps, G. (2013). Scan path entropy and arrow
plots: Capturing scanning behavior of multiple observers.
Frontiers in Psychology , 4.
https://doi.org/10.3389/fpsyg.2013.00996
Jarodzka, H., Balslev, T., Holmqvist, K., Nyström, M., Scheiter,
K., Gerjets, P., & Eika, B. (2012). Conveying clinical
reasoning based on visual observation via eye-movement modelling
examples. Instructional Science , 40(5),
813–827.
https://doi.org/10.1007/s11251-012-9218-5
Jarodzka, H., Holmqvist, K., & Gruber, H. (2017). Eye tracking
in educational science: Theoretical frameworks and research
agendas. Journal of Eye Movement Research , 10(1),
1–18.
https://doi.org/10.16910/jemr.10.1.3
Jarodzka, H., Scheiter, K., Gerjets, P., & Van Gog, T. (2010).
In the eyes of the beholder: How experts and novices interpret
dynamic stimuli. Learning and Instruction, 20(2),
146–154.
https://doi.org/10.1016/j.learninstruc.2009.02.019
Jarodzka, H., Van Gog, T., Dorr, M., Scheiter, K., & Gerjets,
P. (2013). Learning to see: Guiding students’ attention via a
Model’s eye movements fosters learning. Learning and
Instruction, 25, 62–70.
https://doi.org/10.1016/j.learninstruc.2012.11.004
Kleiner, M., Brainard, D. H., Pelli, D., Ingling, A., Murray, R.,
& Broussard, C. (2007). What’s new in psychtoolbox-3. Perception,
36(14), 1–16.
Krebs, M.-C., Schüler, A., & Scheiter, K. (2019). Just follow
my eyes: The influence of model-observer similarity on Eye
Movement Modeling Examples. Learning and Instruction, 61,
126–137.
https://doi.org/10.1016/j.learninstruc.2018.10.005
Krebs, M.-C., Schüler, A., & Scheiter, K. (2021). Do prior
knowledge, model-observer similarity and social comparison
influence the effectiveness of eye movement modeling examples for
supporting multimedia learning? Instructional Science
, 49(5), 607–635.
https://doi.org/10.1007/s11251-021-09552-7
Lai, M.-L., Tsai, M.-J., Yang, F.-Y., Hsu, C.-Y., Liu, T.-C., Lee,
S. W.-Y., Lee, M.-H., Chiou, G.-L., Liang, J.-C., & Tsai,
C.-C. (2013). A review of using eye-tracking technology in
exploring learning from 2000 to 2012. Educational Research
Review, 10, 90–115.
https://doi.org/10.1016/j.edurev.2013.10.001
Litchfield, D., Ball, L. J., Donovan, T., Manning, D. J., &
Crawford, T. (2010). Viewing another person’s eye movements
improves identification of pulmonary nodules in chest x-ray
inspection. Journal of Experimental Psychology: Applied
, 16(3), 251–262.
https://doi.org/10.1037/a0020082
Lowe, R., & Boucheix, J.-M. (2011). Cueing complex animations:
Does direction of attention foster learning processes?
Learning and Instruction , 21(5), 650–663.
https://doi.org/10.1016/j.learninstruc.2011.02.002
Mautone, P. D., & Mayer, R. E. (2001). Signaling as a
cognitive guide in multimedia learning. Journal of
Educational Psychology, 93, 377–389.
Meltzoff, A. N., & Moore, M. K. (1977). Imitation of facial
and manual gestures by human neonates. Science, 198(4312),
75–78.
https://doi.org/10.1126/science.198.4312.75
Niehorster, D. C., Andersson, R., & Nyström, M. (2020). Titta:
A toolbox for creating PsychToolbox and Psychopy experiments with
Tobii eye trackers. Behavior Research Methods, 52(5),
1970–1979.
https://doi.org/10.3758/s13428-020-01358-8
Niehorster, D. C., Cornelissen, T., Holmqvist, K., & Hooge, I.
(2019). Searching with and against each other: Spatiotemporal
coordination of visual search behavior in collaborative and
competitive settings. Attention, Perception, &
Psychophysics , 81(3), 666–683.
https://doi.org/10.3758/s13414-018-01640-0
Niehorster, D. C., Gullberg, M., & Nyström, M. (2024).
Behavioral science labs: How to solve the multi-user problem.
Behavior Research Methods, 56 , 8238-8258.
https://doi.org/10.3758/s13428-024-02467-4
Niehorster, D. C., & Nyström, M. (2025). A toolbox for
creating networked eye-tracking experiments in Python and MATLAB
with Tobii eye trackers. Behavior Research Methods, 57,
8238-8258.
https://doi.org/10.3758/s13428-024-02467-4
Nyström, M., & Holmqvist, K. (2008). Semantic Override of
Low-level Features in Image Viewing – Both Initially and Overall.
Journal of Eye Movement Research , 2, 1–11.
Nyström, M., Niehorster, D. C., Cornelissen, T., & Garde, H.
(2017). Real-time sharing of gaze data between multiple eye
trackers–evaluation, tools, and advice. Behavior Research
Methods, 49(4), 1310–1322.
https://doi.org/10.3758/s13428-016-0806-1
Olsson, P. (2007). Real-time and Offline Filters for Eye
Tracking. Master thesis, KTH, Sweden.
Pelli, D. (1997). The VideoToolbox software for visual
psychophysics: Transforming numbers into movies. Spatial
Vision, 10, 437–442.
Rayner, K. (Ed.). (1992). Eye Movements and Visual
Cognition: Scene Perception and Reading . Springer New
York.
https://doi.org/10.1007/978-1-4612-2852-3
Rayner, K. (2009). The 35th Sir Frederick Bartlett Lecture: Eye
movements and attention in reading, scene perception, and visual
search. Quarterly Journal of Experimental Psychology
, 62(8), 1457–1506.
https://doi.org/10.1080/17470210902816461
Sheridan, H., & Reingold, E. M. (2017). The holistic
processing account of visual expertise in medical image
perception: A review. Frontiers in Psychology , 8,
1620.
https://doi.org/10.3389/fpsyg.2017.01620
Špakov, O. (2012). Comparison of eye movement filters used in HCI.
Proceedings of the Symposium on Eye Tracking Research and
Applications , 281–284.
https://doi.org/10.1145/2168556.2168616
Špakov, O., Istance, H., Räihä, K.-J., Viitanen, T., &
Siirtola, H. (2019). Eye gaze and head gaze in collaborative
games. Proceedings of the 11th ACM Symposium on Eye Tracking
Research & Applications , 1–9.
https://doi.org/10.1145/3317959.3321489
Strohmaier, A. R., MacKay, K. J., Obersteiner, A., & Reiss, K.
M. (2020). Eye-tracking methodology in mathematics education
research: A systematic literature review. Educational Studies
in Mathematics, 104(2), 147–200.
https://doi.org/10.1007/s10649-020-09948-1
Tunga, Y., & Cagiltay, K. (2023). Looking through the model’s
eye: A systematic review of eye movement modeling example studies.
Education and Information Technologies , 28(8),
9607–9633.
https://doi.org/10.1007/s10639-022-11569-5
Van der Gijp, A., Ravesloot, C. J., Jarodzka, H., Van der Schaaf,
M. F., Van der Schaaf, I. C., Van Schaik, J. P. J., & ten
Cate, Th. J. (2017). How visual search relates to visual
diagnostic performance: A narrative systematic review of
eye-tracking research in radiology. Advances in Health
Sciences Education , 22(3), 765–787.
https://doi.org/10.1007/s10459-016-9698-1
Van Gog, T. (2021). The Signaling (or Cueing) Principle in
Multimedia Learning. In R. E. Mayer & L. Fiorella (Eds.),
The Cambridge Handbook of Multimedia Learning (3rd ed.,
pp. 221–230). Cambridge University Press.
https://doi.org/10.1017/9781108894333.022
Van Gog, T., Jarodzka, H., Scheiter, K., Gerjets, P., & Paas,
F. (2009). Attention guidance during example study via the model’s
eye movements. Computers in Human Behavior , 25(3),
785–791.
https://doi.org/10.1016/j.chb.2009.02.007
Van Gog, T., Kok, E. M., Emhardt, S., Van Marlen, T., &
Jarodzka, H. (2024). Eye movement modeling examples. In A.
Gegenfurtner, & I. Kollar (Eds.), Designing effective
digital learning environments(pp.90-105). Taylor &
Francis.
https://doi.org/10.4324/9781003386131-10
Van Gog, T., & Scheiter, K. (2010). Eye tracking as a tool to
study and enhance multimedia learning [Editorial]. Learning and
Instruction, 20(2), 95–99.
https://doi.org/10.1016/j.learninstruc.2009.02.009
Van Marlen, T., Van Wermeskerken, M., Jarodzka, H., & Van Gog,
T. (2016). Showing a model’s eye movements in examples does not
improve learning of problem-solving tasks. Computers in Human
Behavior, 65, 448–459.
https://doi.org/10.1016/j.chb.2016.08.041
Van Marlen, T., Van Wermeskerken, M., Jarodzka, H., & Van Gog,
T. (2018). Effectiveness of eye movement modeling examples in
problem solving: The role of verbal ambiguity and prior knowledge.
Learning and Instruction , 58, 274–283.
https://doi.org/10.1016/j.learninstruc.2018.07.005
Velichkovsky, B. M. (1995). Communicating attention: Gaze position
transfer in cooperative problem solving. Pragmatics &
Cognition, 3 (2), 199–223.
https://doi.org/10.1075/pc.3.2.02vel
Vig, E., Dorr, M., & Cox, D. (2012). Space-Variant Descriptor
Sampling for Action Recognition Based on Saliency and Eye
Movements. In A. Fitzgibbon, S. Lazebnik, P. Perona, Y. Sato,
& C. Schmid (Eds.), Computer Vision – ECCV 2012
(Vol. 7578, pp. 84–97). Springer Berlin Heidelberg.
https://doi.org/10.1007/978-3-642-33786-4_7
Wang, F., Zhao, T., Mayer, R. E., & Wang, Y. (2020). Guiding
the learner’s cognitive processing of a narrated animation.
Learning and Instruction , 69, 101357.
https://doi.org/10.1016/j.learninstruc.2020.101357
Xie, H., Zhao, T., Deng, S., Peng, J., Wang, F., & Zhou, Z.
(2021). Using eye movement modelling examples to guide visual
attention and foster cognitive performance: A meta‐analysis.
Journal of Computer Assisted Learning , 37(4),
1194–1206.
https://doi.org/10.1111/jcal.12568
Zhang, Y., Pfeuffer, K., Chong, M. K., Alexander, J., Bulling, A.,
& Gellersen, H. (2017). Look together: Using gaze for
assisting co-located collaborative search. Personal and
Ubiquitous Computing ,21 (1), 173–186. https://doi.org/10.1007/s00779-016-0969-x